Software Engineering is Dead
At coreflow we are riding two technological waves:
- AI is about to rewrite entertainment.
- AI is about to rewrite how software is built.
This post is about the second wave: how AI is killing software engineering as we know it, and how to take advantage of the shift.
0. Where are we?
Today, I estimate 80-90% of the code written at coreflow is written by AI.
Two years ago I would have laughed at that. And yes, lines of code is a terrible metric (what about code generators or compilers writing millions of lines?) but AI isn’t just printing tokens. It’s producing the equivalent implementation I would have written manually, at the same or higher quality, at radically higher speed.
What software engineering actually is
I think of software engineering as a pipeline:
- Understand the problem
- Design the solution
- Implement
- Validate end-to-end
- Ship + monitor
- Iterate
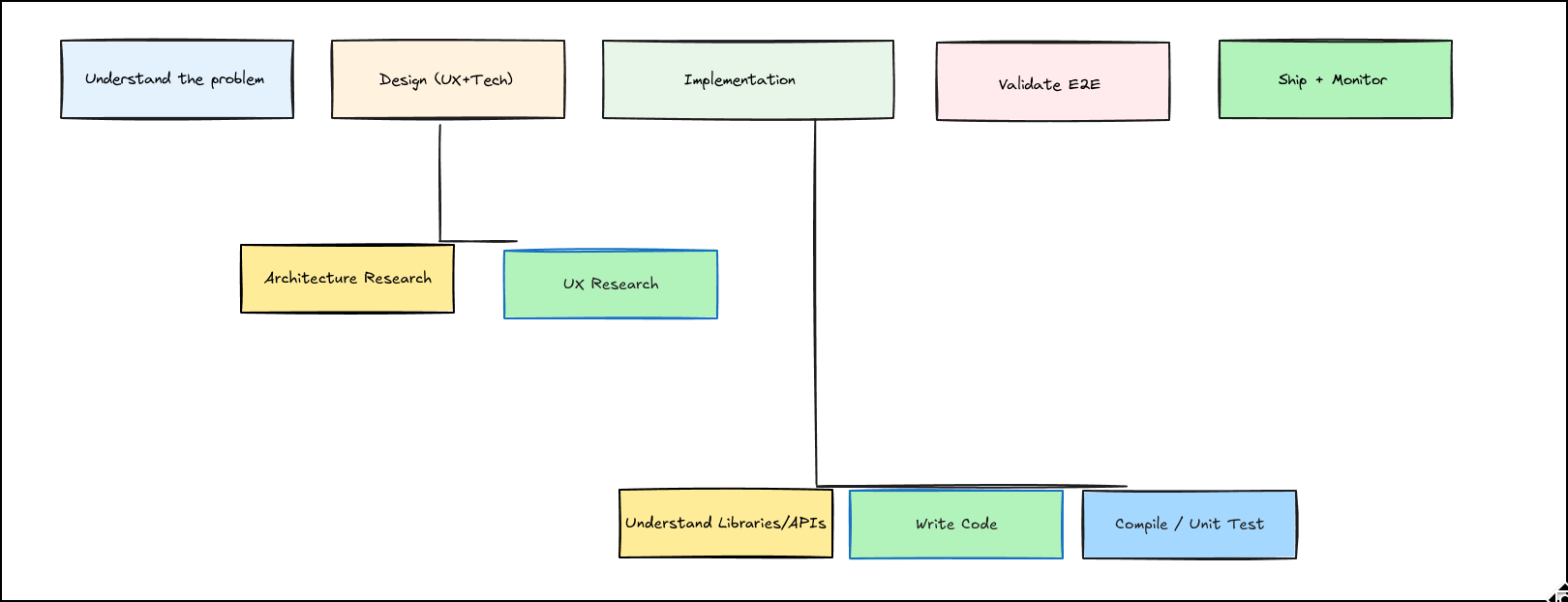
The key claim of this post: AI has already taken over implementation and a significant chunk of design. But we’re nowhere close to harnessing its full potential.
Let me show you how we got here, and where it’s going.
The eras
Copilot Era (~2021)
A glorified autocomplete. It helped with raw typing speed, but I type fast enough that this never took off for me.
I skipped this era entirely.
ChatGPT Era (~2023)
A supercharged documentation reader. It could summarise APIs, explain library patterns, and write simple functions if you scoped them tightly. Every model improvement expanded what it could write.
Status:
- Write code: simple functions, well-scoped
- Understand libraries/APIs: genuinely good at reading docs and explaining them
Cursor Era (~2024)
A huge UX unlock. Index the entire repo, reference many files, make larger edits. AI could finally work beyond a single function.
I skipped this era because I live in VIM, but it was an important transition for the ecosystem.
Claude Code Era (~Feb 2025, Sonnet 3.7)

This was the inflection point.
AI could now change multiple files coherently. It could fix its own type errors, catch lint issues, and iterate until things compiled. For the first time, it worked like a normal engineer would: write, check, fix, repeat.
But it still struggled with anything requiring system-level judgement: migrations, backfills, scaling decisions, production risk. It could get the functional requirements right but didn’t have the context to understand scale.
I used it serially: one agent, watched closely, catching mistakes before they compounded.
Status:
- Write code: multi-file changes
- Libraries/APIs: could research autonomously beyond pretraining (e.g. reading npm package source)
- Verification: compile + unit tests as guardrails
Parallel Claude Code Era (~June 2025, Opus)
I started parallelising: multiple agents running tasks in separate git worktrees, managed via tmux.
Here’s the script I wrote in June that I still use today to spin up a new worktree with editor, agent, and terminal in one command:
Script
#!/bin/bash
set -x
TASK_NAME="$1"
SESSION_NAME="main"
DATE_PREFIX=$(date +%Y%m%d)
WORKTREE_DIR="/home/justin/code/coreflow-repo/worktrees/claude-$DATE_PREFIX-$TASK_NAME"
GIT_REPO_PATH="/home/justin/code/coreflow-repo/coreflow"
if [ -z "$TASK_NAME" ]; then
echo "Usage: $0 <task-name>"
exit 1
fi
mkdir -p "$(dirname "$WORKTREE_DIR")"
git -C "$GIT_REPO_PATH" worktree add "$WORKTREE_DIR" -b "$TASK_NAME"
if [ -f "/home/justin/code/coreflow-repo/.env" ]; then
cp "/home/justin/code/coreflow-repo/.env" "$WORKTREE_DIR/.env"
cd "$WORKTREE_DIR" && ./local/initial_setup.sh
fi
if [ -n "$TMUX" ]; then
tmux new-window -n "$TASK_NAME" -c "$WORKTREE_DIR"
tmux split-window -h -c "$WORKTREE_DIR"
tmux split-window -v -c "$WORKTREE_DIR" -t "$TASK_NAME".1
tmux send-keys -t "$TASK_NAME".0 "vim CURRENT_CLAUDE_TASK.md" C-m
tmux send-keys -t "$TASK_NAME".1 "cd $WORKTREE_DIR && opencode" C-m
tmux send-keys -t "$TASK_NAME".2 "pnpm install" C-m
else
tmux has-session -t "$SESSION_NAME" 2>/dev/null || tmux new-session -d -s "$SESSION_NAME"
tmux new-window -t "$SESSION_NAME" -n "$TASK_NAME" -c "$WORKTREE_DIR"
tmux split-window -t "$SESSION_NAME":"$TASK_NAME" -h -c "$WORKTREE_DIR"
tmux split-window -t "$SESSION_NAME":"$TASK_NAME".1 -v -c "$WORKTREE_DIR"
tmux send-keys -t "$SESSION_NAME":"$TASK_NAME".0 "vim CURRENT_CLAUDE_TASK.md" C-m
tmux send-keys -t "$SESSION_NAME":"$TASK_NAME".1 "cd $WORKTREE_DIR && opencode" C-m
tmux send-keys -t "$SESSION_NAME":"$TASK_NAME".2 "pnpm install" C-m
tmux select-window -t "$SESSION_NAME":"$TASK_NAME"
tmux attach-session -t "$SESSION_NAME"
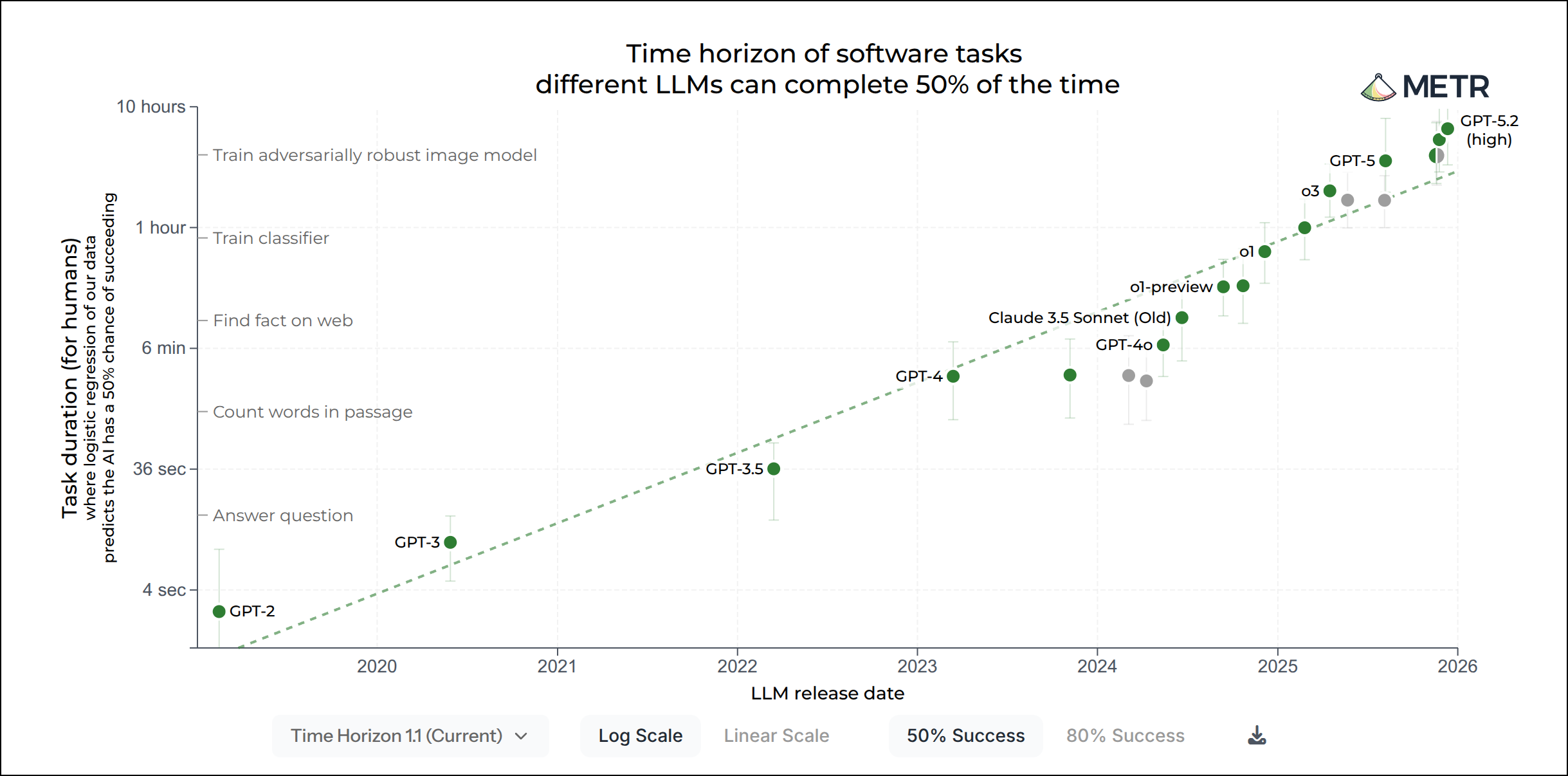
fiAt this point the workflow changed fundamentally. Agents could execute entire feature tasks with minimal hand-holding, especially with planning mode and crisp acceptance criteria. Based on METR: Sonnet could complete tasks that took 1 hour; Opus could complete tasks that took 5.
Where they still failed:
- Anything requiring context outside the repo (database migrations, production backfills, vendor integrations)
- Anything irreversible (one-way data changes, risky infrastructure)
- Anything requiring taste (product polish, “is this the right thing to build?”)
And crucially: I started trusting the agent enough that I didn’t read every line of code. I validated behaviour instead.
Status:
- Write code: end-to-end features spanning multiple files and services
- Design: can research, plan, and propose full architectures including infrastructure and data layer
- Verification: LSP built in, catches errors as it goes. Works like a human would
AI Employee Era (~2026)
This is the era we’re entering now. I think we’re about to experience another shift.
The shift
From early 2025 to early 2026, we went from AI writing basic functions to multiple AI agents running tasks end-to-end. Software engineering has already fundamentally changed.
AI has taken over implementation. It does it better than humans and only continues to improve.
The bottleneck is now validating end-to-end behaviour before launch. The agent will still get things wrong, but it’s blocked on us testing and telling it what’s broken. It’s started doing well at architectural design, but still struggles when it lacks context for the full system: how to run backfills, how things scale, what’s actually in production.
The rate of change is staggering. So where do we go from here?
1. Breaking down AI dimensions
When I think about where AI is versus where it’s going, I think in five dimensions:
- Context: does the model have the right information?
- Intelligence: is it smart enough to solve the problem?
- Verifiability: can it confirm the problem is solved?
- Closed loop: can it execute without human handoffs?
- Proactivity: does it act without being prompted?
My core belief: intelligence in the foundational models are already shockingly strong. The real bottleneck is context, verification, and loop closure. The more we remove humans from the loop and instead give agents the right tools and context, the better off we’ll be.
1.1 Context
The biggest area of immediate impact is giving agents context on the entire system, not just code.
The evolution of context in AI development:
- ChatGPT era: you copy/paste relevant code into the chat
- Cursor era: index the entire repo so the model knows where to look
- Claude Code era: bash commands to traverse the codebase autonomously
But “context” isn’t just code. Real engineering requires visibility into the whole system:
- Datadog logs and metrics
- PostHog analytics and conversion data
- Customer reports (Discord, support tickets)
- Database shape, size, and constraints
- Deploy history, incidents, rollout rules
Today, humans do the boring bridging work: detect a problem, collect the evidence, then ask an LLM to reason about it. If an agent could see a spike in error logs directly, it could fix or escalate immediately. If it could see conversion cratering, it could investigate.
Give the agent direct access to system context, and it becomes dramatically more capable.
1.2 Intelligence
This is the most over-discussed dimension. Benchmarks are saturating. LLMs solve international olympiad problems. Within a year we went from “barely writes a function” to “ships multi-service features.” And it’s still accelerating.
We already live in a world where AI can implement faster than most engineers and reason about architecture at a strong first-pass level. The scary part is they’re only going to get smarter. We wouldn’t write assembly by hand or calculate square roots manually. There’s no good reason we’ll be hand-writing API integrations in a few years.
Not all hope is lost. The most effective leaders don’t have to be the most productive individual contributors. And, just like writing code, LLMs are tools we can leverage to produce products and impact the world.
Prepare for a world where AI is better at implementation than you. Hint: It’s already here.
1.3 Verifiability
This is where the future of AI-first productivity lives.
The key insight: the recent breakthrough in LLMs is reinforcement learning with verified rewards. Think coding or maths, domains where you can check if the answer is correct. All modern LLMs are trained this way, which makes them extremely good at problems where the solution can be verified.
Verification starts simple: does the code compile? Do unit tests pass? But this is a limited framing. We can allow long-running agents to verify whether an experiment provided an uplift in conversion. We can have agents check with users whether a fix actually resolved their issue.
The tighter the verification loop, the more effective the agent becomes.
Build systems that let agents verify their own work. That’s the multiplier.
1.4 Closed loop
Closing the loop means removing human handoffs at every step.
In the ChatGPT era, the model had to ask you to compile its code. Imagine if your best engineer had to ask you to run the compiler every time. That’s how slow it was. Now Claude Code checks types and catches issues without intervention.
Today, agents can get a technically valid implementation but still can’t verify expected behaviour without someone testing it manually. Soon, with multiple labs working on computer use, agents will interact with browsers, dashboards, and production tooling directly. They’ll validate by using the product end-to-end.
The ideal state: the agent ships a change, validates it (tests + E2E + metrics), rolls out safely, and you only see a summary. Or nothing at all, because it just works.
Remove yourself from the loop so agents can be truly autonomous.
1.5 Proactivity
Today’s agents sit idle until prompted. That’s backwards.
They should be continually monitoring parts of the system to see if there’s work to be done:
- Watch error logs for new patterns
- Watch conversion for drops
- Watch Discord for user complaints
- Correlate recent commits with incidents
These tasks are boring and repetitive. Agents don’t get bored. Agents don’t forget to check. Anytime you find yourself doing something repetitive, that should become an agent cron job.
Anything repetitive and monitorable should be an agent running continuously.
2. Entering the AI Employee Era
[Coming soon] How do we fully take advantage of the model capabilities.
3. What does the ideal company look like in 3 years?
[Coming soon] What is the terminal state?
Small team, massive leverage, bleeding edge AI, real impact.